2025; SleeperAgent (AI707 Advanced Topics in DRL Project)
- Guining Pertin
- May 9, 2025
- 9 min read

Updated: Mar 15
About the Project
I worked on this project in KAIST with Myriam Schonenenberger, AI Dept., for the AI707 course. The project was called SleeperAgent: Dreaming from a Third Perspective, and it was about "dreaming" up a 3rd person view given only the wrist camera view for a manipulator to improve task efficiency and success rates.
The github repo is: https://github.com/otoshuki/sleeperagent
Note that everything written here was just copy pasted from the original report we wrote in LaTeX for the course, and so it might not be arranged in the best way possible for a blogpost.
TL;DR
Wrist cameras lose information if the robot's end-effector moves, discarding global context.
We utilize Zero-1-to-3, a novel-view synthesis diffusion model fine-tuned on our generated simulation dataset with Low-Rank Adaptation (LoRA).
We utilize Dreamer-V3 (a world-model-based RL algorithm) that utilizes both the wrist and the generated 3rd person view image together to learn the latent dynamics.
We found that our algorithm performs similar to and better than the ablations (it's a course project, we didn't have time for a lot of comparisons).
We also noted that by delaying our generated image to every 20 frames of input, the agent seems to learn better with our hypothesis being higher priority provided to wrist image but utilizing learned representations from the generated 3rd person view like an anchor.
Introduction
Robotic manipulators equipped with eye-in-hand cameras observe their workspace exclusively through the end-effector. While this placement simplifies calibration, it discards global context: objects or landmarks disappear from view as the wrist moves, and a representation of the robot's pose with respect to these objects is missed. A fixed, third-person camera would supply the missing information, yet installing and calibrating extra cameras is often impractical in many real-world scenarios. Object occlusions and space constraints are other obstacles to setting up such global scene cameras. We therefore pose the question:
Can a third-person view be synthesized on-the-fly from the current wrist image and leveraged to improve policy learning?
Our answer combines two recent advances. First, we adopt Dreamer-V3 - a world-model reinforcement-learning (RL) algorithm that trains a latent dynamics model and improves its policy purely through imagination [1]. Second, to hallucinate the missing viewpoint, we use the single-image novel-view diffusion model Zero-1-to-3 [2] fine-tuned on the simulation dataset with Low-Rank Adaptation (LoRA) [3]. The result is a fast training pipeline with real-time deployment that produces third-person views and feeds them to Dreamer's world model before they reach the actor–critic.
In this project, our main contributions and working principles are as follows.
Fine-tuning of Zero-1-to-3 using LoRA on the transformer blocks.
An integration scheme that injects diffusion-generated views into Dreamer-V3 with no architectural changes.
A systematic study comparing wrist-only (W), oracle third-person (T), fused wrist+oracle (W+T), and fused wrist+diffusion generated observations (W + T̃) (tilde T btw, wix does not render it correctly).
Related Work
Prior works highlight the value of multi-view inputs for robotic manipulation. VISTA [4] and LookCloser [5] demonstrate that multiple viewpoints enhance policy robustness and performance by providing richer scene understanding. VISTA, in particular, shows that the synthesizing of novel views from a single image can act as an effective data augmentation, improving the resilience to camera pose variations and perceptual shifts during testing. Inspired by these findings, we focus on online RL with a constrained wrist-camera input to synthesize third-person views.
A natural baseline is to assume access to such a third-person camera, which we refer to as the oracle view (T). In its absence, the next best alternative is to estimate this view using a novel view synthesis method applied to egocentric wrist images, yielding an approximate third-person view (T̃) that can then be used for policy learning. To this end, we were initially inspired by VISTA to adopt the ZeroNVS [6] approach, which leverages a Zero123 [ 2 ] diffusion model coupled with Neural Radiance Fields (NeRF) fitting to enforce 3D consistency across synthesized views. However, due to resource constraints and the impracticality of training a NeRF model for each input frame, we opted instead to use the Zero123 backbone as a more lightweight alternative.
Methodology
Overview

Our overall architecture combines the view synthesis from Zero-1-to-3 with a Dreamer-V3 agent, acting on a simulation in robosuite [7, 8]. In Figure 1, we can see:
Part a) visualizes the camera setups with one camera being mounted on the wrist
of the robot arm (W) and the other camera given a fixed third person view of the setup (T).
Part b) shows how the Zero-1-to-3 model is used to generate the third person view (T̃).
Part c) one timestep of the world model training is visualized showing the enhanced observation x_t.
View Synthesis
Zero-1-to-3 generates a novel view (T̃) from an input image (W) and the current camera pose (p_W , R_W), given the goal camera pose (p_T , R_T), where p∗ and R∗ refers to position and rotation from the scene frame to the corresponding camera frame. It uses a latent diffusion architecture with an autoencoder (E, D), and a denoiser U-Net ϵ_θ .
To condition the denoising process towards novel view generation, it uses CLIP encoder to create the conditioning embedding cond(W, p_W , R_W , p_T , R_T) [2] which is passed to the U-Net. Then, a DDIM scheduler [9] is used with timsteps t ∼ [1, 1000] to generate the required latent vector zt at each timestep. The latent at any time step t can then be decoded to obtain the required view T̃ = D(z_t). We will refer to the overall view synthesis step as T̃ = G_t(W, p_W , R_W , p_T , R_T).
Data Collection and Fine-Tuning
We collect a simulation dataset using robosuite and robomimic, capturing wrist images, end-effector poses, corresponding third-person views and its poses. The dataset is generated with a mix of random actions and teleoperated actions. While the simulation dataset originally provides transformation of the end-effector with respect to the robot’s base frame, we transform it with respect to the center of the scene where the goal tasks are to be performed. The same is performed for the third person view frame which is attached opposite to the robot’s base. Altogether, we obtain the samples {W, pW , RW , T, pT , RT }, and consider the fine-tuning objective

For fine-tuning, we freeze the autoencoderKL, CLIP encoder and most parts of the U-Net. We consider adding low-rank adaptation only to the query, key and value components of the cross attention layers in the U-Net, referred to as θ′. We also limit the DDIM steps to 20 since we prefer faster inference at the cost of lower quality results.
Dreamer-V3 with SheepRL
Dreamer-V3 learns a latent world model from observations and actions, predicting future states and rewards following the recurrent state-space model (RSSM) architecture. Policies are trained within this model via imagination, reducing environment interactions and improving sample efficiency. We use SheepRL’s [10] implementation with fabric acceleration for multi-GPU training.
Agent Training Loop
SleeperAgent’s pseudocode is shown in algorithm 3.4. Note that the only change with respect to the Dreamer-V3 algorithm, highlighted in red, is the augmentation of the observation with the generated third person view. The genrated view was sampled every 20 frames. The low update frequency was necessary for two reasons: limited training times, and inconsistency between generated views even for two similar frames.

Experiments

We train Dreamer-V3 policies in the robosuite block stacking environment (200 steps, 20Hz, reward shaping enabled) for 175K steps, comparing four configurations: wrist-only (W), oracle third-person (T), fused wrist + oracle (W+T), and fused wrist + synthesized third-person (W+T̃). Synthesized views are generated every 20 frames using Zero-1-to-3, fine-tuned with LoRA. Results are averaged over two seeds, except for W+T̃, where only one seed was run due to computational constraints.
For our experiments we try to validate the following hypotheses:
H1. W: Should perform worse compared to all other cases.
H2. T: Should have average performance.
H3. W+T: Should have higher performance and stable training but have a slower learning progress.
H4. W+T̃: Should perform similar to W+T at least, if not better.
Results

Figure 2 shows an example rollout of the wrist view with the generated 3rd-person view T̃. The oracle 3rd-person view T is shown as reference.
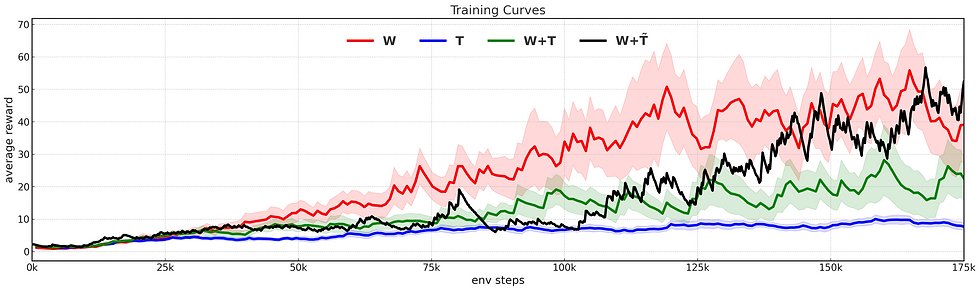
In the above figure, ach curve is smoothed using an exponential moving average with a factor of 0.9 and shaded with ±0.5 of the smoothed variance over 2 seeds. The W+T̃ curve is based on a single seed due to computationalconstraints.
Figure 3 shows the average reward as a function of the environment training steps. Contrary to our expectations, the W+T and the T configuration underperformed compared to the baseline W. The wrist-only policy achieved faster learning and higher rewards than all other cases. However it had higher variance and failed in cases where the task was not directly visible at the start or left the view during the episode. While the higher performance was not expected, we expected the case of occlusions and bad views to hinder the training. Hypothesis H1 was proved incorrect.
We find that the second configuration, T, achieved the lowest average reward from the episodes conflicting hypothesis H2. We posit two potential factors: firstly, due to larger static regions in the image, and secondly, higher difficulty in understanding the robot’s position and identity through the image inputs.
By considering both wrist and third-person views we hypothesized that we should receive higher performance at the cost of more training time. From the training curves we find that this holds true, especially with lower variance in training. We expected the training to be slower mainly due to the larger observation space for the world model to learn upon. As inferred through LookCloser [5], there should be a shared representation between the two views allowing it to "understand" better.
To our surprise, we found our approach W+T̃ to perform better than W+T configuration. The learning progress in W+T̃ was comparable to W with the training stability of W+T. While the diffusion generated views were noisy compared to T, we suspect that keeping the image fixed for 20 input frames caused the world model to bias towards the wrist images while T̃ still provided a global context to anchor the learning process. All our original hypotheses were proved incorrect during our experiments.
Conclusion
Our project explores synthesizing third-person views from wrist images to enhance robotic manipulation with Dreamer-V3. While we hypothesized that W+T̃ would match W+T performance, with the latter having the highest performance, our results reveal the wrist-only baseline W to perform the best if given favorable initial conditions. Surprisingly, W+T̃ outperforms W+T, despite W+T’s artifact-free oracle views and identical input shape. We hypothesize that W+T̃’s fixed synthesized views (every 20 frames) bias the world model toward the wrist view, reducing reliance on noisy global context and stabilizing training.
Additionally, artifacts in W+T̃ may act as implicit regularization, preventing overfitting to redundant features present in W+T’s oracle view. The poor performance of W+T suggests that high-fidelity multi-view inputs increase encoder complexity and introduce irrelevant information, outweighing global context benefits. These findings highlight the need to balance input relevance and model capacity in multi-view RL. Future experiments, outlined below, will refine view synthesis quality, temporal consistency, and encoder architecture to leverage synthesized views effectively, aiming to surpass W’s performance.
Future Experiments
To improve the W+T̃ configuration, we propose the following experiments with hypotheses that address current shortcomings:
Enhanced View Synthesis Quality
Experiment: Fine-tune Zero-1-to-3 with a larger, more diverse dataset, incorporating varied lighting, object textures, and backgrounds. Explore alternative diffusion models with explicit 3D consistency (e.g., Stable Zero123).
Hypothesis: Poor synthesis quality (artifacts, distortions) confuses the world model, reducing learning efficiency. Higher-fidelity views will align W+T̃ closer to W+T.
Adaptive Observation Fusion
Experiment: Implement an attention-based fusion mechanism to weigh wrist and synthesized views dynamically, reducing reliance on noisy generated views. Train with curriculum learning, gradually increasing the weight of T̃.
Hypothesis: High-dimensional input overwhelms Dreamer-V3’s encoder. Selective fusion will focus on relevant features, improving sample efficiency.
Temporal Consistency in View Synthesis
Experiment: Generate views with different sampling times (vs. 20) or interpolate intermediate views using optical flow. Alternatively, train a recurrent view synthesis model to maintain temporal coherence.
Hypothesis: Temporal discontinuities from infrequent synthesis could disrupt latent dynamics if left unchecked.
Simplified World Model Architecture
Experiment: Modify Dreamer-V3’s encoder to handle multi-view inputs more efficiently (e.g., separate encoders for W and T̃ with shared latent space). Reduce latent dimensionality to mitigate overfitting.
Hypothesis: The current model struggles with complex multi-view inputs. A tailored architecture will improve learning stability and speed.
References
[1] Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023.
[2] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023.
[3] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022.
[4] Stephen Tian, Blake Wulfe, Kyle Sargent, Katherine Liu, Sergey Zakharov, Vitor Guizilini, and Jiajun Wu. View-invariant policy learning via zero-shot novel view synthesis. arXiv preprint arXiv:2409.03685, 2024.
[5] Rishabh Jangir, Nicklas Hansen, Sambaran Ghosal, Mohit Jain, and Xiaolong Wang. Look closer: Bridging egocentric and third-person views with transformers for robotic manipulation. IEEE Robotics and Automation Letters, 7(2):3046–3053, 2022.
[6] Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, et al. Zeronvs: Zero-shot 360-degree view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9420–9429, 2024.
[7] Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning. In arXiv preprint arXiv:2009.12293, 2020.
[8] Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. In arXiv preprint arXiv:2108.03298, 2021.
[9] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
[10] EclecticSheep. Sheeprl: Train and deploy reinforcement learning agents faster. https://eclecticsheep.ai/, 2024. Accessed: 2025-06-13.


Comments